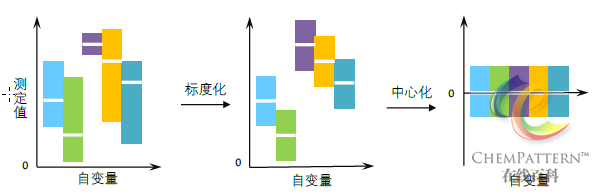
从化学分类学角度而言,复杂体系样本个体所携带的化合物组成种类和构成比例信息,通常要比单纯的化合物含量信息更稳定、也对分类更有价值。由于生物样品的个体差异,经常同一分组的组内样本的含量波动在绝对值上要超过组间样品在比例上差异,此时无论使用原始的定性或定量数据,都会对正确区分组间和组内样品带来较大的干扰,如图12-8所示。
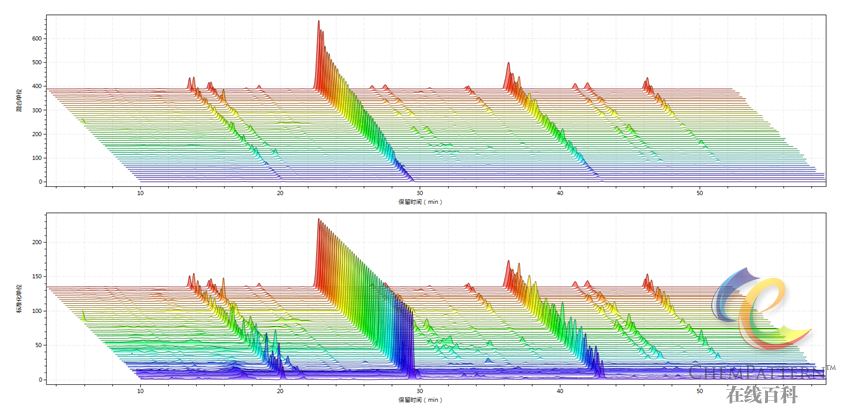
注:上图显示中药材北柴胡(Bupleurum chinense DC.)中皂苷类成分指纹图谱的原始图谱,显示组内差异较大。下图示意经过针对观测的数据归一化变换后,突出了该类样本共有特征的模式图谱。
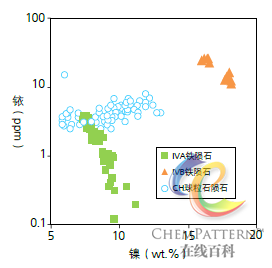
注:铁陨石的性质由各类定性、定量指标所描述,显示各指标的类型和计量范围差异极大,在分类前需要针对变量进行数据预处理。
| 亚型 | 镍 (wt.%) |
钴 (mg/g) |
镓 (μg/g) |
硅酸盐 | 代表 晶型 |
|---|---|---|---|---|---|
| IAB | 9.50 | 4.9 | 63.6 | + | 八面体 |
| IIAB | 5.65 | 4.6 | 58.63 | - | 六面体 |
| IIIAB | 8.33 | 5.1 | 19.79 | - | 八面体 |
| IVA | 8.51 | 4.0 | 2.14 | - | 八面体 |
| IVB | 17.13 | 7.6 | 0.23 | - | 无结构 |
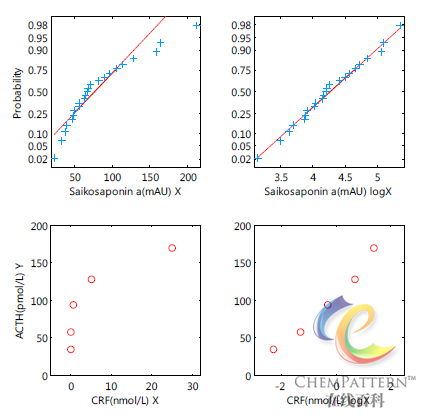
上图:中药材北柴胡(B. chinense DC.)中各样本的柴胡皂苷a峰面积在经过对数转换后与正态分布符合良好;下图:经对数转换的不同剂量标准促肾上腺皮质激素释放因子(CRF)与其刺激离体大鼠垂体前叶合成的肾上腺皮质激素(ATCH)的量之间呈良好的线性关系。