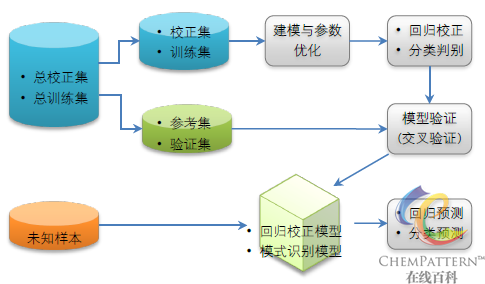
模式识别技术,亦称模式分类,在机器学习(machine learning)中是指为给定的输入样本数据赋予与其最接近的分类“标签”的一类算法的统称。回归模型可视为模式识别模型的一个特例,此时连续形式的回归预测值将取代人为设定的分类预测值,二者在分析流程上高度一致。一个包含完整的建模、交叉验证,以及预测分析的回归分析和模式识别建模过程的基本流程如下图所示。
模式识别技术根据学习过程(或称训练过程)可分为有监督(supervised learning,或称有老师,老师即指训练集)和无监督两类。前者又分为参数和非参数方法,其中在分析化学中常见的算法包括k最近邻法(k-NN)、偏最小二乘判别(PLS-DA)、簇类独立软模式法(SIMCA)、典型相关分析(CCA)、支持向量机(SVM)、贝叶斯(Bayes)判别法、BP(反向传播)人工神经网络等,后者主要包括聚类分析和自组织映射(SOM)人工神经网络等。二者的主要差别在于各实验样本所属的类别是否预先已知。一般说来有监督的分类较为常用,但通常需要提供大量已知类别的样本进行学习,在复杂体系分析中完全满足这一点有时存在困难,此时无监督分类方法的研究就显示十分必要。对于上述算法的详细介绍请参考本说明书对应章节。
化学模式识别(chemical pattern recognition)是一类在分析化学领域中常用的模式识别方法,其主要涉及对未知样品的类别或等级进行预测分类的问题,即定性分析问题。对于此类判别任务,其分析的侧重点不在于获取某个或某些成分的精确含量,而在于对其所属类别进行准确的判断。因此模式识别较回归分析而言,涉及了更为复杂的样本多变量数据的特征提取,以及获得决策性信息等分类和学习过程。
模型性能(质量)评价是建模环节的重要组成部分,对于保证模型的泛化预测能力,预防模型的过拟合现象而言具有重要意义。其通常结合交叉验证(12.20)进行。涉及模型性能评价的参数有很多,现举例一二如下:
分类k的拒识率(false rejection rate),是指验证过程中将第k类样本错误归属为非k类的比例,即为模型犯I型错误(type I error,亦称假阴性)的比率。
分类k的误识率(false acceptance rate),是指验证过程中将非k类样本错误归属为k类的比例,即为模型犯II型错误(type II error,亦称假阳性)的比率。