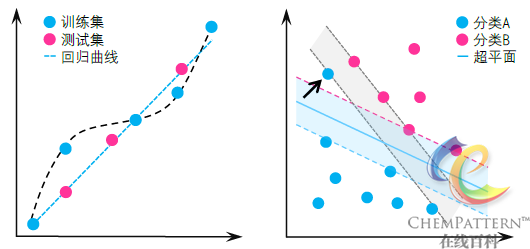
左图:对数据点的线性回归(y=aX)和多项式(次数=6)曲线回归。显示多项式拟合的回归模型误差MSE较小,但预测能力较差,即模型的泛化能力不足;
右图:在图中所示的支持向量机训练过程中,过拟合的模型将受到箭头所示的离群样本较大的影响,导致其分类模型并非最优解;
右图:在图中所示的支持向量机训练过程中,过拟合的模型将受到箭头所示的离群样本较大的影响,导致其分类模型并非最优解;
交叉验证(cross validation, CV)是一种统计学上的模型验证技术,用于评价一种分析方法当施用于独立数据集时的泛化能力(generalization ability),并对所建立的预测模型的性能给出精确的评估。其基本思想是先将数据样本集划分为互补的子集(subsets),并根据其中一个子集(在模式识别中称为训练集,training set;在回归建模中则称为校正集,calibration set)进行建模,并利用互补子集(称为验证集,validation set)对模型的性能进行验证。
交叉验证对模型预测性能的评估过程也即是对模型参数的优化筛选过程,通过对不同配置参数下的模型依次进行交叉验证,所获得的预测误差均值最低的一组模型参数即为最优参数。通过交叉验证可以防止模型过拟合现象的发生,确保获得的模型具有良好的泛化能力,其对于模式识别及回归建模而言具有重要的意义。
交叉验证主要包括以下几种方法:
将训练样本集随机地分成k个大小基本一致的子集。将其中k-1个子集作为训练集用于建立模型,利用剩余的一个子集作为验证集,对所获得模型的预测进行评估。重复以上过程k次,则每个子集都有且只有一次机会作为测试集,最后根据k次迭代后得到的平均值来估计期望泛化误差。
在实践中,该类方法中使用较多的是7~10重交叉验证,过小的k值(如k=2)将造成结果的波动性较大。
此外为使结果更加可靠,在k重交叉验证的基础上还可采用蒙特卡洛随机采样(Monte-Carlo random sampling)的方法,连续多次生成不同的随机子集划分方案并依次进行交叉验证,最终验证结果将根据随机次数取平均值。
该方法可视为K重交叉验证法的极限情况,即k=训练样本集大小n。该方法的步骤与k重交叉验证的不同之处在于每次取出第i个样本作为单独的验证集,而将剩余n-1个样本作为测试集进行建模。该方法的步骤共重复n次。
相较于前面介绍的k重交叉验证,留一交叉验证具有以下优缺点: