12.23 k最近邻法
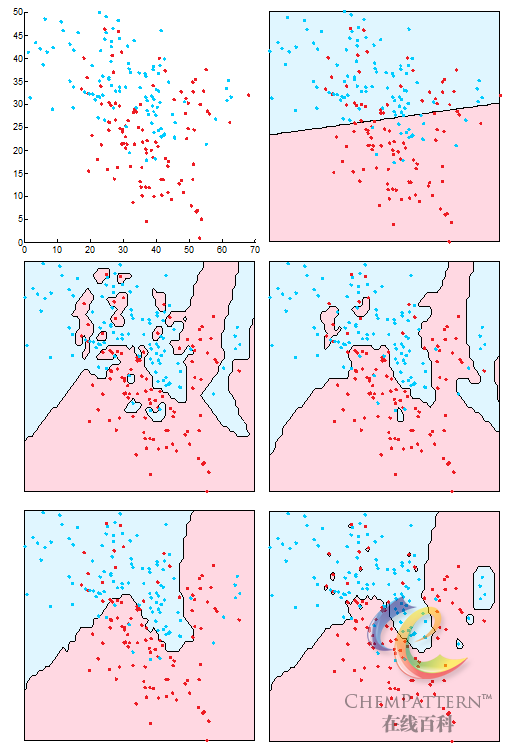
k最近邻法(k-nearest neighbours, k-NN)模型由Fix 和Hodges于1951年提出,是模式识别和学习机中最基础的模型之一。k最近邻法用于模式识别时的基本原理较简单,其分类依据是基于特征空间中与待测样本最邻近的k个训练集样本的归属(投票数),如图12-37所示。
kNN在实际使用中一般采用改进后的加权投票法,即:
{V_{sample}} = \sum {{V_i}/{D_i}}
其中{D_i}(i = 1,2, \cdots ,k)是待测样本与k个最邻近样本之间的距离函数,Vi为第i个近邻样本的投票(分类预测)。加权方法引入了对样本间距离影响程度的度量,并且避免了k个不同分类样本的投票数相同时所导致的分类困难,因此提高了结果的可靠性(图12-38)。ChemPattern所采用的kNN方法即为加权法。
k最近邻法与线性模型
在模式识别中,K最近邻法和线性模型(线性学习机)是最基础的学习方法,很大一部分的统计学习算法本质上都是对k最近邻法和线性模型的各自扩展。二者具有以下一些异同点:
- k最近邻法和线性模型代表了统计学习中的两个极端,即最松泛的指定模型和最严格的限制模型;
- k最近邻法和线性模型都属于统计决策理论,其相同之处在于都以样本均值来逼近数学期望,但二者对模型的假设具有本质区别。线性模型假设回归函数f(x)近似线性,而k最近邻法假设f(x)可由一个局部恒定的函数逼近,后者在理论上可以逼近任意函数;
- 假设每个分类的样本都服从正态分布,则线性模型的性能将优于k最近邻法。反之如果样本所服从的分布并不规则,那么k最近邻法模型将会工作得更出色。
k最近邻法还具有以下特点以及在应用中需要注意的事项:
- k最近邻法属于典型的非参数方法,可用于高维线性不可分的重叠类(图12-38),并总能获得稳健的结果。因此适合于复杂体系的样本分析;
- k最近邻法要求各个分类所包含的样本数大体一致。如果样本数不均衡(如某个类的样本容量相对很大),将导致待测样本的k个近邻中大容量类的样本总是居于多数。此时采用加权投票方法可改善分类效果;
- 对仿真实验结果的大量统计分析表明,k最近邻法的分类性能仅次于支持向量机,而明显优于线性模型(最小二乘拟合)、朴素贝叶斯和人工神经网络方法;
- k最近邻法模型需要存储整个训练集,并且对每一个待测样本进行分类预测都需要计算其与全体训练集样本之间的距离,因此数据存储量和计算量都相对较大,但可通过降维及采用改进算法等途径提高计算性能;
- k最近邻法的维数灾难。数据向量在高维(>10维)空间中的分布特性与传统的低维(≤3维)空间有着本质的不同。在高维下欧氏距离等距离函数将失去意义,这是因为随着维度的提高,特征空间的体积将快速膨胀,造成样本之间的位置不断远离,形成稀疏分布,此时从任意一个待测样本的位置观察,k个最近邻样本与其距离都将大致相等(下式),即分布在以其为中心的超球体的表面。
\mathop {\lim }\limits_{d \to \infty } \frac{{{\text{dis}}{{\text{t}}_{\max }} - {\text{dis}}{{\text{t}}_{\min }}}}{{{{\operatorname{dist} }_{\min }}}} \to 0
因此当自变量较多时,在开展k最近邻法模式识别前,应对数据进行降维预处理,如主成分分析(PCA)或自组织映射人工神经网络(SOM)等,以改善高维度对于分类的负面影响;
- 最佳的k值选取需要结合实际问题及样本集规模而定,并通过模型的交叉验证予以确认。通常而言,较大的k值将降低分类中的噪音,但同时会削弱判定边界的确定性。