偏最小二乘判别分析视图提供该类分析的多元统计视图,以及结果的详细汇总表格,如图11-12所示。方法原理详见12.17偏最小二乘回归。
偏最小二乘判别分析的参数与偏最小二乘回归是一致的,主要涉及保留潜变量个数的选择,以及交叉验证方法(12.20)的配置。详见下表:
| 项目名称 | 说明 | 选项 |
|---|---|---|
| 偏最小二乘回归 | 设置偏最小二乘回归的参数 | |
| 保留潜变量个数 | 设置PLS模型的潜变量个数,该值一般由交叉验证结果推导。设为0则按可能最大值自动设置,如下式min(n-1, m-1)。 | 取值≥2 |
| 交叉验证 | 选择交叉验证的方法 | 无、k重交叉验证、留一交叉验证 |
| 交叉验证k值 | 设定交叉验证k值,即训练集子集抽取和迭代验证的次数,取值通常以7-10为宜 | 取值≥2 |
| 随机模拟次数 | 当样品较多且k值较小时,增加随机模拟次数以提高交叉验证的可靠性 | 取值范围:1~100 |
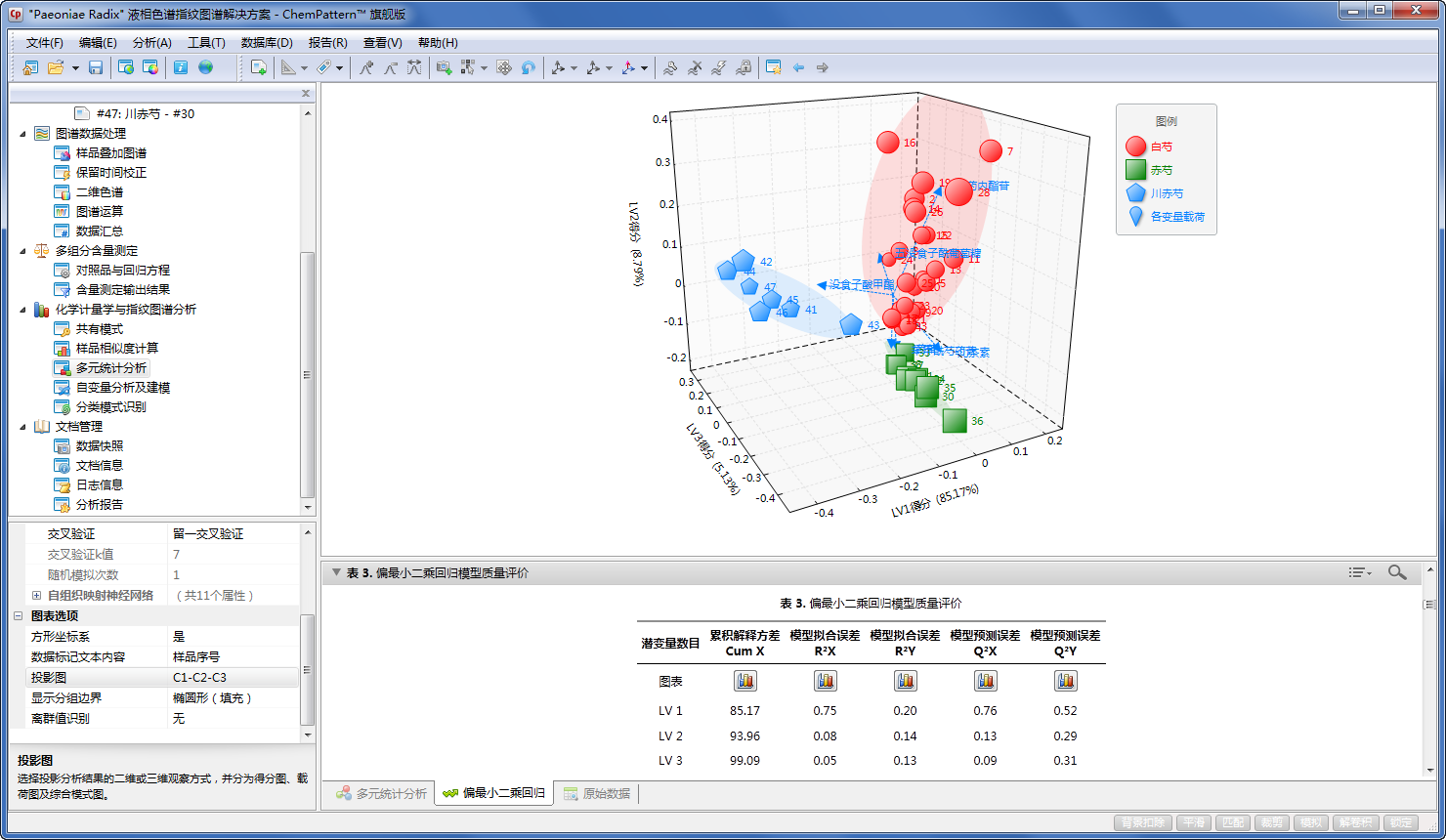
关于偏最小二乘判别的潜变量(LVs)投影图的显示及设置请参考11.3.2主成分分析。
偏最小二乘判别输出栏分别提供以下分析结果统计列表及对应的多元统计图形:
1)偏最小二乘回归方程
| 表头名称 | 说明 |
|---|---|
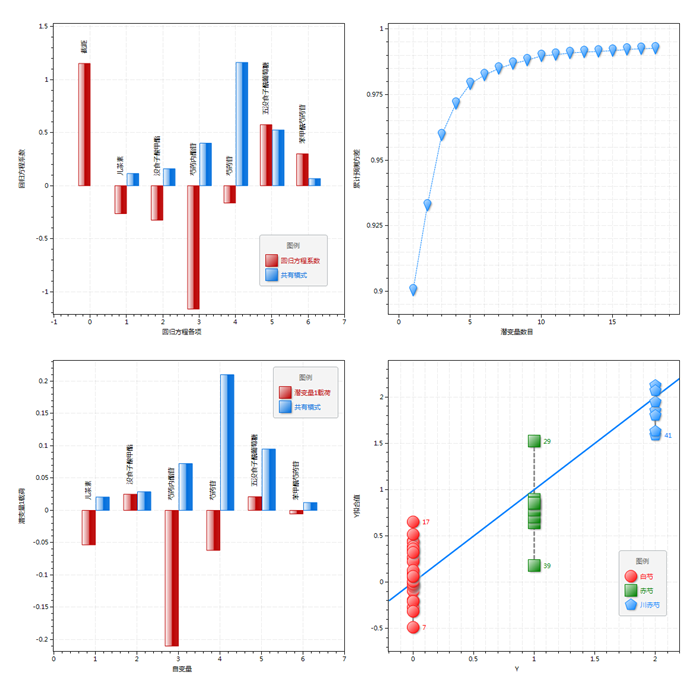
| 回归方程 | 显示回归方程,包括截距和各项系数。在偏最小二乘回归中,将根据因变量的个数分别显示每个Yi的回归方程。 偏最小二乘方程回归系数(图11‑13-1) |
| 决定系数R² | 回归方程的决定系数R2值 |
| 潜变量数 | 显示当前回归模型中保留使用的潜变量个数 |
表2)偏最小二乘回归方程假设检验。按检验水平α=0.05,拒绝或接受假设H0=数据间不存在显著的线性回归关系。
表3)偏最小二乘回归模型质量评价
| 表头名称 | 说明 |
|---|---|
| 潜变量数目 | 潜变量序号或者保留的潜变量个数 |
| 模型X解释率 R²X | 模型的X累积方差解释率R²X(图11‑13-2),即对于X的拟合程度,1为最佳。 |
| 模型Y解释率 R²Y | 模型的Y累积方差解释率R²Y,即对于Y的拟合程度,1为最佳。 |
| 模型X预测率 Q²X | 模型的X预测方差率Q²X,即对于验证集中X的拟合程度,1为最佳。使用时需要开启交叉验证。 |
| 模型Y预测率Q²Y | 模型的Y预测方差率Q²Y,即对于验证集中Y的拟合程度,1为最佳。需要开启交叉验证。通常而言,模型所应保留的潜变量个数应以Q2Y最大值处为准。 |
表4)偏最小二乘回归潜变量载荷。只显示前k个潜变量(k≤10)
| 表头名称 | 说明 |
|---|---|
| 成分名称 | 自变量的化合物名称或序号。 |
| 潜变量LVn载荷 | 潜变量LVn的载荷向量,即该潜变量与自变量之间的线性变换关系。图11‑13-3。内容说明详见11.3.2主成分分析对应表格项下。 |
表5)偏最小二乘回归潜变量得分。只显示前k个潜变量(k≤10)
| 表头名称 | 说明 |
|---|---|
| 样品序号,样品图谱 | 样品序号及名称 |
| 潜变量LVn | 显示所有样品的潜变量得分。内容说明详见11.3.2主成分分析对应表格项下。 |
表6)回归拟合值与残差分析。残差分析是检查样本数据是否符合模型条件的工具。
| 表头名称 | 说明 |
|---|---|
| ID,样品名称 | 显示每个样品的编号和名称 |
| Y拟合值 | 偏最小二乘回归因变量预测(图11‑13-4)。显示每个因变量的Y值与其拟合值的相关性,对于偏最小二乘判别分析而言,Y即为样品的分组信息。 |
| 标准化残差 | 偏最小二乘回归残差(图11‑13-5) 显示每个样本的拟合值及其标准化残差: {e'_i} = \frac{{{Y_i} - {{\hat Y}_i}}}{{\sqrt {M{S_{RES}}} }} 通常情况下,ei’近似服从均数为0,方差为1的标准正态分布。超过正态分布±1.96σ(P=0.05)的样品属于离群值,表明其回归拟合值的偏差具有显著意义。 |
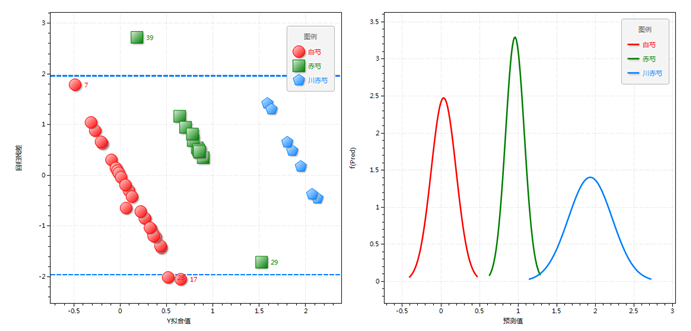
表7)偏最小二乘判别(PLS-DA)预测分类概率分布(仅在模式识别中显示)。
| 表头名称 | 说明 |
|---|---|
| 分类 | 显示的样品分组 |
| 均值,方差 | 组内样品的Y拟合值的均值和方差,即标准正态分布的参数。 |
| 绘图 | 偏最小二乘判别预测分类概率分布(图11‑13-6)。图中显示每个分类的偏最小二乘回归Y拟合值的正态分布正态分布图像,以及与邻近分类的关系,从而可用于直观判断分类的可靠性及难易程度。 |
表8)未知样品回归预测结果(仅在自变量分析中显示)。如果样品中包括因变量Y未知的样品,则显示对应的回归预测结果 。未知样品的设定方法详见11.1.3导入样品支持数据。