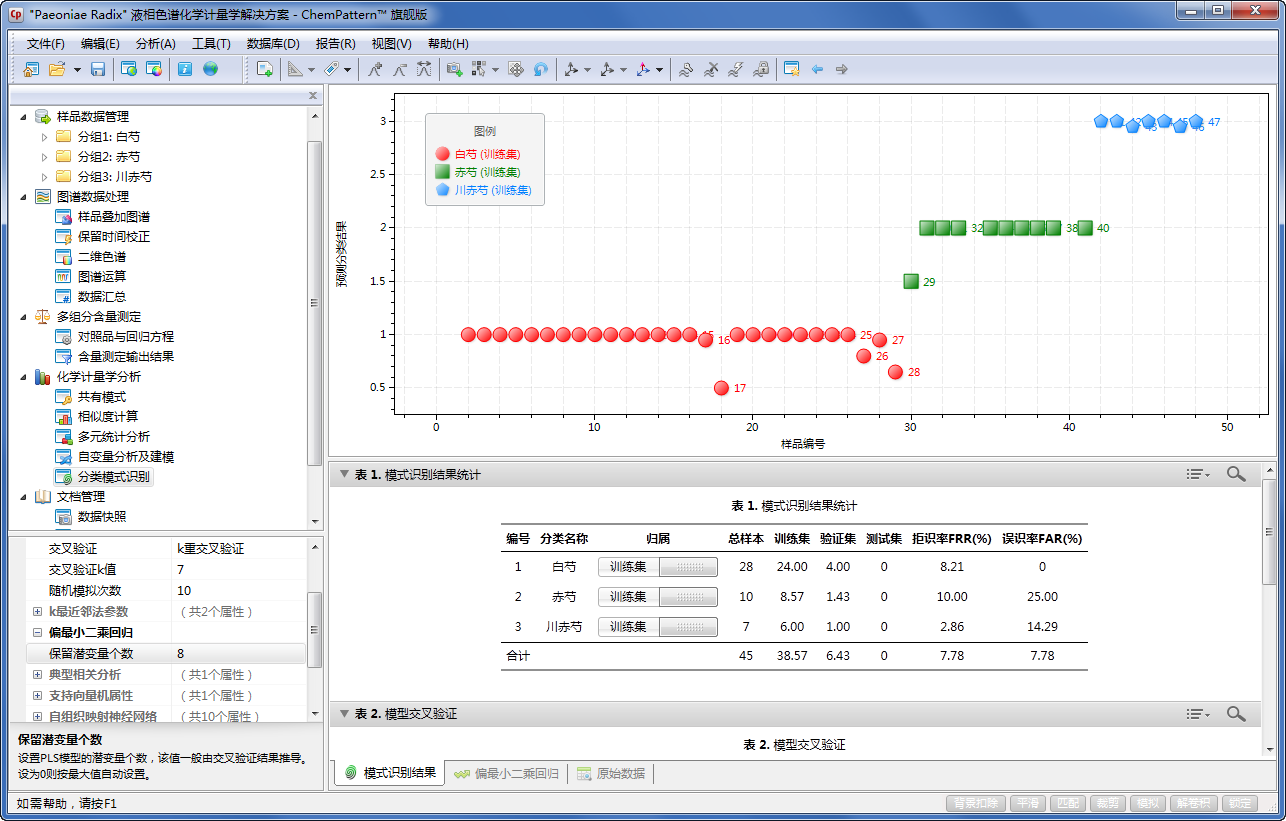
图中显示k值1-10的k最近邻法交叉验证结果,提示k=1或2时模型的识别率最高
模式识别界面提供高度集成的各类化学模式识别技术的建模及未知样品判别功能。建模方法选择、模型参数设定、交叉验证、训练集和测试集配置、模型质量评价以及各模式识别方法的详细输出图表等均可在同一个界面下系统地完成并生成详细的分析结果。
ChemPattern提供了6种具有代表性的经典模式识别方法,包括:
对于各算法的原理和使用方法说明详见以下各小节。此外,模型质量评价是评估建模成功与否的重要手段,其原理详见12.20 交叉验证方法。
以下对模式识别视图中的各方法通用内容进行介绍。
对模式识别属性栏中各个算法通用的参数设定的说明如下:
| 项目名称 | 说明 | 选项 |
|---|---|---|
| 模式识别 | 进行图谱的模式识别。需要选择训练集、验证集(可选)和测试集(可选)。 | |
| 模式识别算法 | 选择有监督或无监督的模式识别算法进行各样本集的预测和分类 | 有监督模式识别:k最近邻法(kNN)、偏最小二乘判别分析(PLS-DA)、典型相关分析(CCA)、簇类独立软模式(SIMCA)、支持向量机(SVM)、无监督模式识别:自组织聚类人工神经网络(SOM) |
| 数据预处理 | 选择对数据进行预处理的方法,从而规范化数据并提高分析结果质量。 | 无:针对观测:标准化、均一化、标度化、中心化;针对变量:标准化、均一化、标度化、中心化;全局:二进制化、自然对数变换、平方根变换 |
| 模型质量评价 | 设置进行回归或模式识别模型的质量评价的方法和参数 | 详见12.20 交叉验证方法。 |
| 交叉验证 | 选择交叉验证的方法 | 无、k重交叉验证、留一交叉验证 |
| 交叉验证k值 | 设定交叉验证k值,即训练集子集抽取和迭代验证的次数,取值通常以7-10为宜 | 取值范围:k≥2 |
| 随机模拟次数 | 当样品较多且k值较小时,增加随机模拟次数以提高交叉验证的可靠性 | 取值范围:1~100 |
在视图的模式识别结果散点图中(图11-27),将根据所选模式识别方法和配置动态显示当前模型的模式识别结果。该散点图具有以下设定:
在视图下方的列表及输出窗口中,依次显示模式识别结果、各模型输出结果,以及原始数据输出。其中模式识别结果窗口汇总了模型训练和预测结果,以及模型质量信息等。
表1. 模式识别统计结果
| 表头名称 | 说明 |
|---|---|
| 分类名称 | 显示每个样品分组的名称。未归属在分类中的样本将不参与模式识别过程 |
| 归属 | 设定该分类属于训练集还是测试集,如为训练集,则软件自动分配验证集。如果当前分类不包含有效样本,则该选项不可用。 |
| 总样本 | 显示该分类中参与计算的总样本数 |
| 训练集 | 如果为训练集,则显示训练集尺寸。如果启用交叉验证,则训练集为非整数。 |
| 验证集 | 如果为训练集,则显示所自动分配的测试集尺寸。需启用交叉验证。验证集大小等于该分类的总样本数除以交叉验证的k值。 |
| 测试集 | 如果为测试集,则显示该分类中需要预测分类的样本数 |
| 拒识率FRR(%) | 拒识率(False Rejection Rate)即为模型犯I型错误(Type I Error,亦称假阴性)的比率。需启用交叉验证。对于一些模式识别算法而言,被一个分类拒识的样本意味着将被另一个分类误识,但对一些较严格的预测模型来说其分类并非互斥关系,被拒识的样本有可能将被判定为无归属。 |
| 误识率FAR(%) | 误识率(False Acceptance Rate)即为模型犯II型错误(Type II Error,亦称假阳性)的比率。需启用交叉验证。 |
| 合计 | 合计上述各数据集的所包含样本数,以及汇总模型的拒识率和拒识率 |
注意该表格显示的统计结果是基于当前参数设置的模型,而非交叉验证过程中使用的其它模型。下表是一个模式识别模型的留一法交叉验证结果的输出示例:
| 编号 | 分类名称 | 归属 | 总样本 | 训练集 | 验证集 | 测试集 | 拒识率FRR(%) | 误识率FAR(%) |
|---|---|---|---|---|---|---|---|---|
| 1 | Astragalus membranaceus | 训练集 | 9 | 8.70 | 0.30 | 0 | 0 | 11.11 |
| 2 | Astragalus mongholicus | 训练集 | 11 | 10.63 | 0.37 | 0 | 9.09 | 0 |
| 3 | Astragalus floridus | 训练集 | 5 | 4.83 | 0.17 | 0 | 0 | 0 |
| 4 | Astragalus ernestii | 训练集 | 5 | 4.83 | 0.17 | 0 | 0 | 0 |
| 合计 | 30 | 29.00 | 1.00 | 0 | 3.33 | 3.33 |
表2. 模型交叉验证
启用交叉验证功能后,该列表将显示当前模型经过交叉验证所获得的验证集识别率。识别率是评价模型预测质量及分类性能的重要指标之一,其对模型泛化能力的评估是其它方法不能替代的。如果当前预测模型支持可调参数的交叉验证(如k最近邻法中的k值,偏最小二乘判别中的潜变量LV数等),则显示不同参数下模型的识别率,如图11-28。
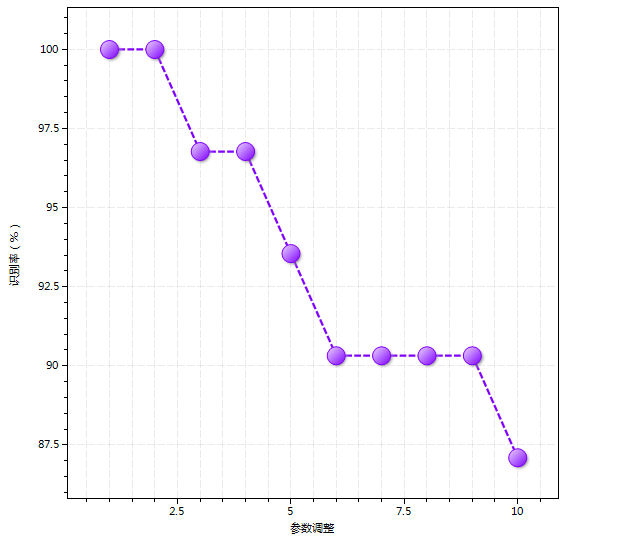
表3. 模式识别样品预测结果。该列表显示测试集内所有待测样本的分类预测结果。不同模式识别方法的分类预测结果表格内容不同,因此分别在对应章节中予以说明。