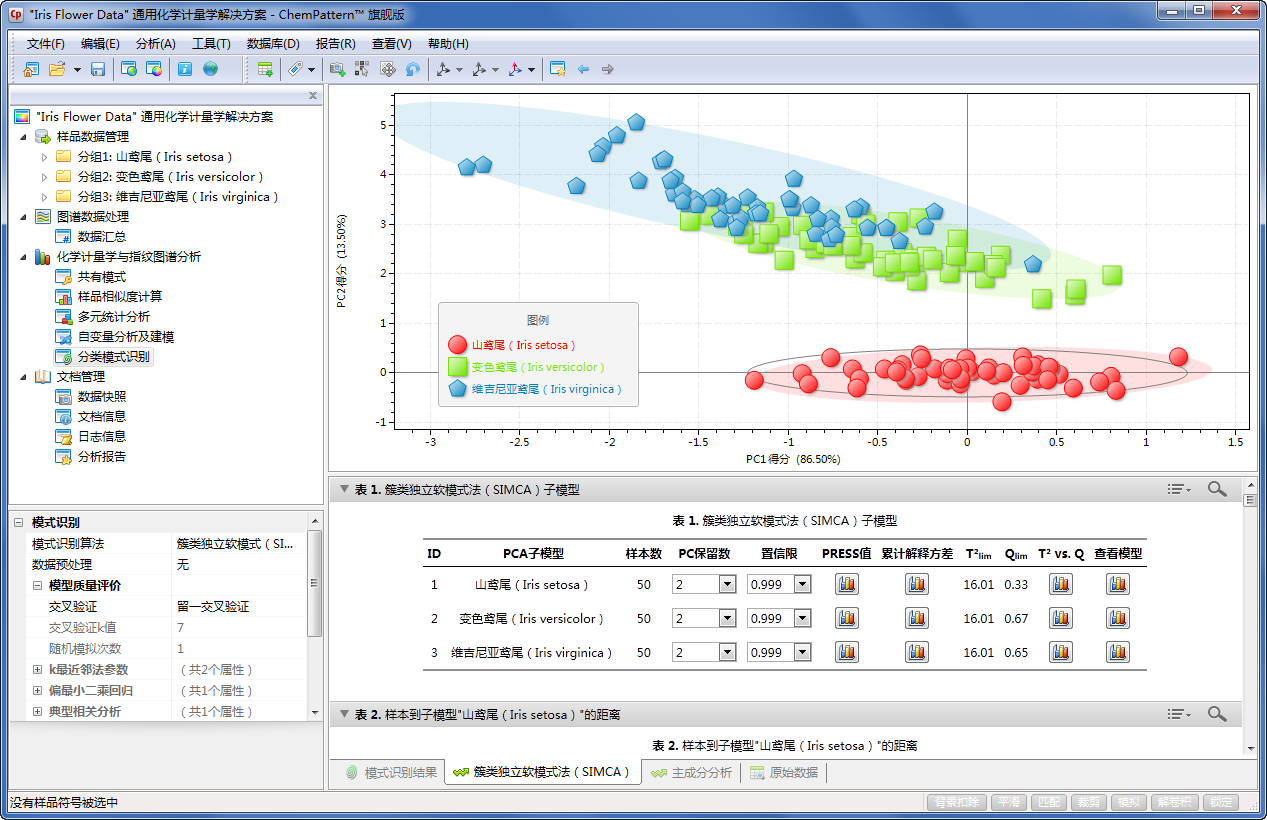
该视图提供支持簇类独立软模式(SIMCA)模式识别的参数配置、详细结果输出和相关多元统计图表。方法原理详见12.25 簇类独立软模式法。
模式识别结果列表中表3.模式识别样品预测结果的定义如下。
| 表头名称 | 说明 |
|---|---|
| 样品ID及名称 | 显示测试集的样品编号及名称 |
| T2 | 测试集样本与每个分类所代表PCA模型拟合后的Hotelling’s T2统计量的相对值。0≤T2≤1。 |
| Q | 测试集样本与每个分类所代表PCA模型拟合后的残差Q的相对值。0≤Q≤1。 |
| d | T2与Q的加权统计值, d = \sqrt {{{({Q_r})}^2} + {{(T_r^2)}^2}} |
| 预测分类 | 综合SIMCA中各分类对应的模型预测值,如全部d > \sqrt 2 ,则该测试集样本不属于任何一个分类,显示为N/A,否则显示d < \sqrt 2 的所有分类,其中d最小值所在的分类即为样本的最可能归属。 |
簇类独立软模式法输出栏分别提供以下分析结果统计列表及对应的多元统计图形:
表B1. 簇类独立软模式法子模型
该表格汇总了SIMCA中各个PCA模型的设定及参数信息,并可进一步访问指定的子模型,详见下表:
| 表头名称 | 说明 |
|---|---|
| ID、PCA子模型 | 显示PCA模型对应的分类编号和名称 |
| 样本数 | 分类中的有效样本数,即训练集容量 |
| PC保留数 | PCA模型中的主成分保留数k,可选范围为1~min(m,n) -1,其中m为分类样本数,n为自变量数 |
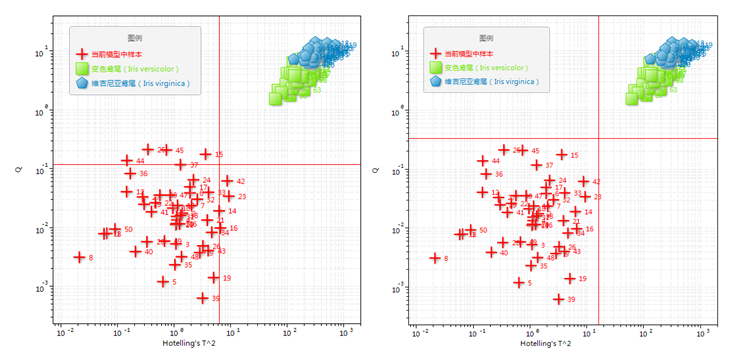
| 置信限 | 0.95,0.99,0.999。置信限越大,则模型的分类界限越宽松(图11‑30-1)。但可能会在降低拒识率的同时提高误识率。 |
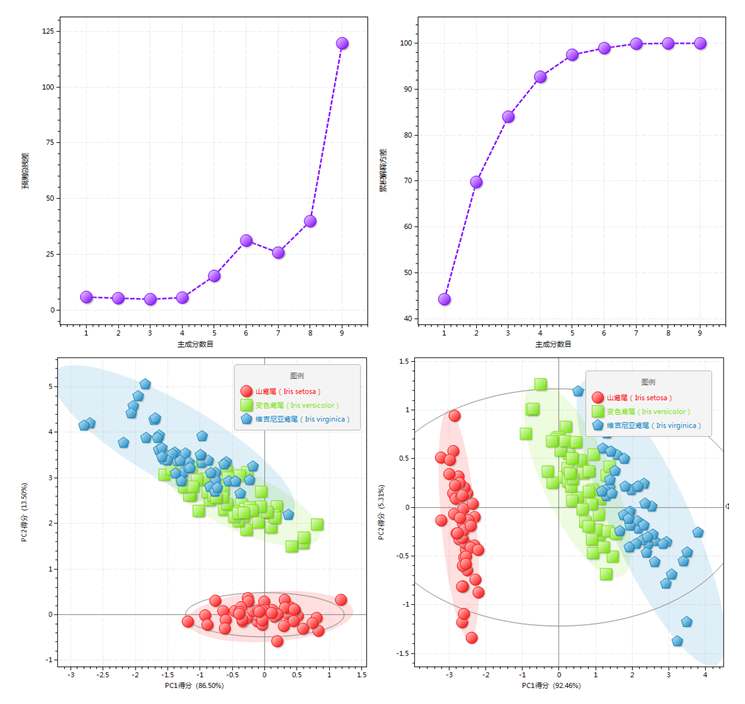
| PRESS值 | 模型的预测残差平方和(图11‑30-3)。典型的PRESS值将随着主成分保留数目k值的增加而呈现先抑后扬的趋势,通常应选取残差最小处的主成分个数。PRESS值的计算涉及交叉验证,因此需要首先设定模式识别交叉验证方法。 |
| 累计解释方差 | 模型中前k个主成分的累计解释方差(图11‑30-4),通常以高于70%为宜 |
| T2lim | 根据模型中训练集样本T2统计值分布情况计算获得的F分布置信限 |
| Qlim | 根据模型中训练集样本残差Q分布情况计算获得的正态分布置信限 |
| T2 vs. Q | 显示log T2 vs. log Q散点图(图11‑30-1,2)。图中当前PCA模型的训练集样本以加号符号标识以示区别。在理想情况下,当前模型的训练集样本应位于第3象限(表明与模型拟合较好),其他分类的训练集样本应位于第2象限。 |
| 查看模型 | 切换至对应的PCA模型结果输出界面,并显示对应的PCA模型的得分图(图11‑30-5)。 |
表B2及以下分别显示构成各PCA模型的训练集样本的T2和Q统计值,可对应于图11-30-1或2中所示意的当前模型中样本的坐标值。
主成分分析输出栏显示当前所查看的PCA模型的相关信息。如果未指定具体的模型,则默认显示第一个。有关该输出栏的具体内容详见11.3.2主成分分析。